QualifyEye
Unsupervised representation learning approach for image quality evaluation
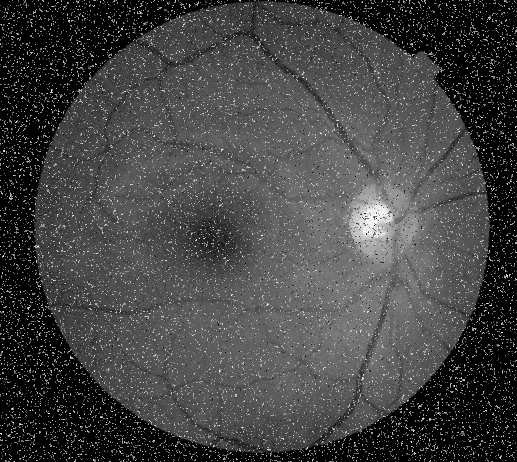
This project will be an opportunity to create an automated data cleaning tool, which will be highly beneficial for speeding up image data grading.
There are a number of research projects using machine learning on retinal image scans to detect and identify various conditions such as Age-related Macular Degeneration (AMD), Diabetic Retinopathy, as well as a variety of inherited conditions such as Stargardts and Retinitis Pigmentosa. These approaches all apply to retinal scans taken from the same machine, in a handful of different imaging modalities.
However, frequently the available data comes in an uncurated form, and scan quality can vary significantly. Hence it would be of great use to have some form of automated quality assessment tool that could filter out low-quality scans automatically. This is also of importance to future deployment of these algorithms to ensure they are not applied to low-quality scans.
In this project we aim to investigate various methods of assessing quality of retinal scans, and ultimately develop a universal approach to retinal image quality assessment. This includes looking at “objective” metrics, as well as looking towards some machine-learning based approaches. This will involve working with multiple teams working with retinal images to understand the different challenges associated with evaluating scans from eyes with different conditions.
Background:
Deep learning has played a major role in boosting the automation of various tasks like classification, segmentation, and object detection. However, developing highly performant and accurate models requires the collection of high-quality datasets with the number of examples ranging in the millions. In a medical imaging setting, this is difficult to achieve due to the challenges of image acquisition and imaging artefacts. Additionally, compiling the dataset requires focused time from doctors and imaging technicians to scrutinize the datasets to check for poor-quality examples. Imaging quality assessment is a relatively underexplored topic in ophthalmic data analysis. For deep learning-based AI systems trained on large corpuses of retinal imaging, ascertaining the quality of individual scans is important both to curate good quality datasets (for training and testing different models) Scan quality is often assessed in terms of grade-ability, which is a subjective measure as to how easy it is to identify key anatomical features, and make a correct assessment based on the scan. However, naive image quality estimation approaches are often insufficient, both missing low quality images, as well as misidentifying good quality images as poor quality. This is made more challenging by the fact that poor grade-ability can be due to poor image quality, but also due to the anatomy of the patient, where many dystrophies can cause extensive tissue damage to the retina, making it difficult to identify the usual anatomical features. Different dystrophies can also express very differently, meaning requirements may be different for different conditions. Hence there is a need for better automated quality-assessment tools for retinal images.
Project proposal:
Unsupervised representation learning is a sub-domain of machine learning that learns valuable feature representations from data. These features will have a lower dimensionality than the original data and should ideally exclude unnecessary information from the images while retaining the important content. This method can be a potential way to discriminate between low-quality and high-quality information without the need for explicit labeling, which is what typical deep learning-based image quality studies do currently.
Dataset:
Having connections with Moorfields Eye Hospital, our lab has access to ophthalmic imaging datasets for color fundus photography, optical coherence tomography, and infrared imaging. The choice of the dataset is up to the student. As a start, it would be useful to explore this topic with a simulated poor-quality dataset for investigating the feasibility of the approach. Following this, the student can proceed to implement the strategy on a dataset containing a mixture of good and bad-quality images.Goals
- Investigate data-driven and computer vision approaches to grade-ability assessment
- Implement an approach to automated grade-ability estimation for IRD data for 3 imaging modalities (FAF, IR, and SD-OCT)
- Assess approach based on dataset of human-annotated data
- OPTIONAL: Expand approach to other diseases, such as AMD + DR
Work plan
- Liaise with medical teams at Moorfields and computer scientists at UCL to understand requirements
- Obtain example data
- Inspect data and identify common issues and explore ideas for filtering
- Experiment with different CV approaches
- Look into obtaining human-annotated dataset for training a classifier model


